La pintan como una Sin City online, extrarradio de inmundicia y violencia, muladar para las pesadillas más atroces. Sustancias, asesinos a sueldo, snuff, hacking… Pero no es un extrarradio, qué va, es más bien subsuelo, sustrato, el sustrato, toda aquella existencia virtual que no está indexada en los motores de búsqueda de las redes. Material en línea, páginas web, archivos, bases de datos que son ajenas a los sistemas de rastreo de buscadores como Google, Yahoo, MSN, Bing. Esa invisibilidad (en 1994 la llamaron así, Invisible Web) no es de naturaleza estrictamente delictiva, con voluntad de fraude, aunque claramente la oscuridad alienta el flirteo y la corrupción.
Su nombre, Deep Web, suele acompañarse pedagógicamente con una analogía pesquera que trata de ilustrarla: buscar en Internet resultaría algo así como lanzar una red de arrastre por la superficie del mar, atrapando una considerable cantidad de información; y sin embargo, resultaría insondable aquello que se escapa de las redes en la profundidad. Esa inmensidad oceánica fuera del alcance de la pesca superficial sería la Deep Web. La superficie de navegación tradicional, por defecto (Surf Web), es la que generan y administran los buscadores con su sistema de motores de rastreo, desplegando las llamadas arañas o robots inteligentes que saltan de página en página a través de los enlaces del hipertexto tejiendo referencias y registrando la información del sitio, recurso que sirve para ir catalogando las propias bases de datos de los buscadores y hacer, entre otras cosas, más rápidas sus respuestas.
Pero no todo es superficie, y más allá de ese indexado la Web Profunda ofrecería un volumen de información 500 veces más grande. Según un estudio realizado por la Universidad de Berkeley en 2001 –que suele aducirse como matriz para variopintas extrapolaciones, ver también el artículo de Mickel K. Bergman– por ese año se estimaba el tamaño de la Surf Web (la Web Superficial, visible, indexada) en unos 167 terabytes, mientras que la Web Profunda se cifraba en unos 7500 terabytes. El material no indexado o Deep Web correspondería al 80-96% de la información disponible en la Red, mientras que el indexado o Internet Superficial vendría a ser del orden del 20-4%. Esas oscilaciones se deben a que no parecen existir datos fidedignos al respecto, sino que son extrapolaciones del susodicho estudio de 2001. Hay que tener en cuenta que por aquel entonces el furor de los blogs y las redes sociales todavía no había despuntado, así como que Google era apenas un recién nacido con todo lo que ello conlleva respecto a las posibilidades y potencia de los motores de búsqueda actuales. No obstante estas consideraciones, parece evidente que el volumen de información en la Web Profunda es ostensiblemente superior al de la Web Superficial.
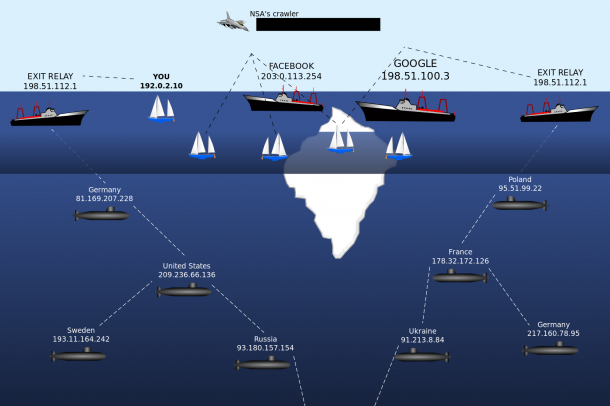
Pero que los motores de búsqueda estándar no registren ciertos sitios no significa que la depravación y la ilegalidad inspiren esos lugares. Por poner un caso que limpie, fije y de esplendor a esa mala reputación del Profundo, la biblioteca o base de datos de del Diccionario de la Real Academia Española (DRAE) es ajena a las arañas (crawlers), por lo que no resultan indexadas las definiciones de las palabras en los buscadores. Muchas otras ingentes bases de datos de servicios o aplicaciones que precisan de una “pregunta directa” por parte del usuario resultan ignoradas. La invisibilidad para los motores de búsqueda puede venir dada por diversos factores, desde la mera indicación del desarrollador de que no quiere que el buscador revise su código (Follow/No Follow en la interfaz de Google) o el olvido de la actualización a los estándares de indexado, hasta los sites protegidos y privados que deliberadamente buscan una grieta de anonimato, ya sea para la degeneración o la iluminación. El formato de determinados archivos también impide que sean registrados por los robots de búsqueda, aunque las posibilidades y la potencia de éstos va abriendo nuevos claros. El propio buscador (la empresa) puede decidir que cierto contenido no es apropiado o interesante e ignorarlo en sus motores, caso de algunas páginas como las que albergan contenido de carácter dinámico, con actualizaciones constantes, en algunos casos susceptibles de albergar laberintos o peticiones pantalla que ralentizan o inutilizan los motores de búsqueda, estrategias conocidas como trampas de araña.
Aunque no todo el monte es orégano, ni toda profundidad averno, la Deep Web es un entorno que precisa de cierta cautela en lo que a protección durante la navegación se refiere. Dado su paisaje y su paisaje, su naturaleza menos intuitiva y automática, es más que conveniente informarse solvente y previamente, así como atenerse al anonimato en las conexiones, de modo que la IP sea lo más difícil posible de rastrear, evitando la exposición de credenciales o registros a través de proxys o intermediarios que hagan pantalla y nos preserven de la información consultada o intercambiada. Dentro de la Deep Web, aunque no es el único, cobra especial importancia el sistema TOR (The Onion Router), una red abierta –originalmente desarrollado el proyecto por el Laboratorio de Investigación Naval de los Estados Unidos– que sirve para navegar anónimamente por la Web Profunda, de manera que los mensajes son cifrados y enviados por un número indeterminados de nodos, complicando el rastreo de la identidad (IP). Su nombre, onion router, vendría a traducirse como encadenamiento de cebolla, haciendo referencia a las sucesivas capas del vegetal como etapas de protección.
A pesar de toda esa aparente invisibilidad del fondo del mar, no hay que descuidar que las sombras de los Estados son alargadas, y el ojo avizor de Sauron no descansa. En resumen, la Deep Web, si bien precisa de cierta cautela a la hora de sumergirse en ella, sobre todo para los menos versados, es un puerto de acceso a bases de datos inmensas, algunas muy rigurosas y de gran calidad, información tangencial, marginal, alternativa pero no necesariamente macabra, morbosa o sensacionalista. Sí, claro, es cierto que hay muchísimo contenido demencial, piratería y enajenación… (¿No resulta también inquietante ese otro Todo en la viña del Google –aunque menos en proporción pues proporciona menos también–? Ya Cernuda atinaba sobre el tema: no solo a imagen y semejanza de dios se hizo el hombre, sino también de su demonio.